







































UDP latency and loss
The UDP latency test measures the round trip time of small UDP packets between the router and a target test server. Each packet consists of an 8-byte sequence number and an 8-byte timestamp. If a packet is not received back within two seconds of sending, it is treated as lost. The test records the number of packets sent each hour, the average round trip time of these and the total number of packets lost. The test will use the 99th percentile when calculating the summarised minimum, maximum and average results on the router.
The test operates continuously in the background. It is configured to randomly distribute the sending of the echo requests over a fixed interval, reporting the summarised results once the interval has elapsed.
By default the test is configured to send a packet every 1.5 seconds, meaning a maximum of 2,400 packets sent per hour. This number will usually be lower, typically around 2000 packets, as by default the test will not send packets when other tests are in progress, or when cross-traffic is detected. A higher or lower sampling rate may be used if desired, up to a maximum of reporting on a one-minute aggregation level, or a minimum of reporting on a 24-hour aggregation level.
The following key metrics are recorded by the test:
- Round-trip latency (mean)
- Round-trip latency (minimum)
- Round-trip latency (maximum)
- Round-trip latency (standard deviation)
- Round-trip packet loss
- Number of packets sent and received
- Hostname and IP address of the test server
Example
In our Spotlight article about the Metaverse we looked at our data to see if our current network infrastructure and technology support a real-time virtual world with no cap on the number of concurrent users. The Metaverse would need networks with very low and consistent latency. This chart shows that latency is a much bigger issue for mobile networks, especially older 3G and 4G networks.
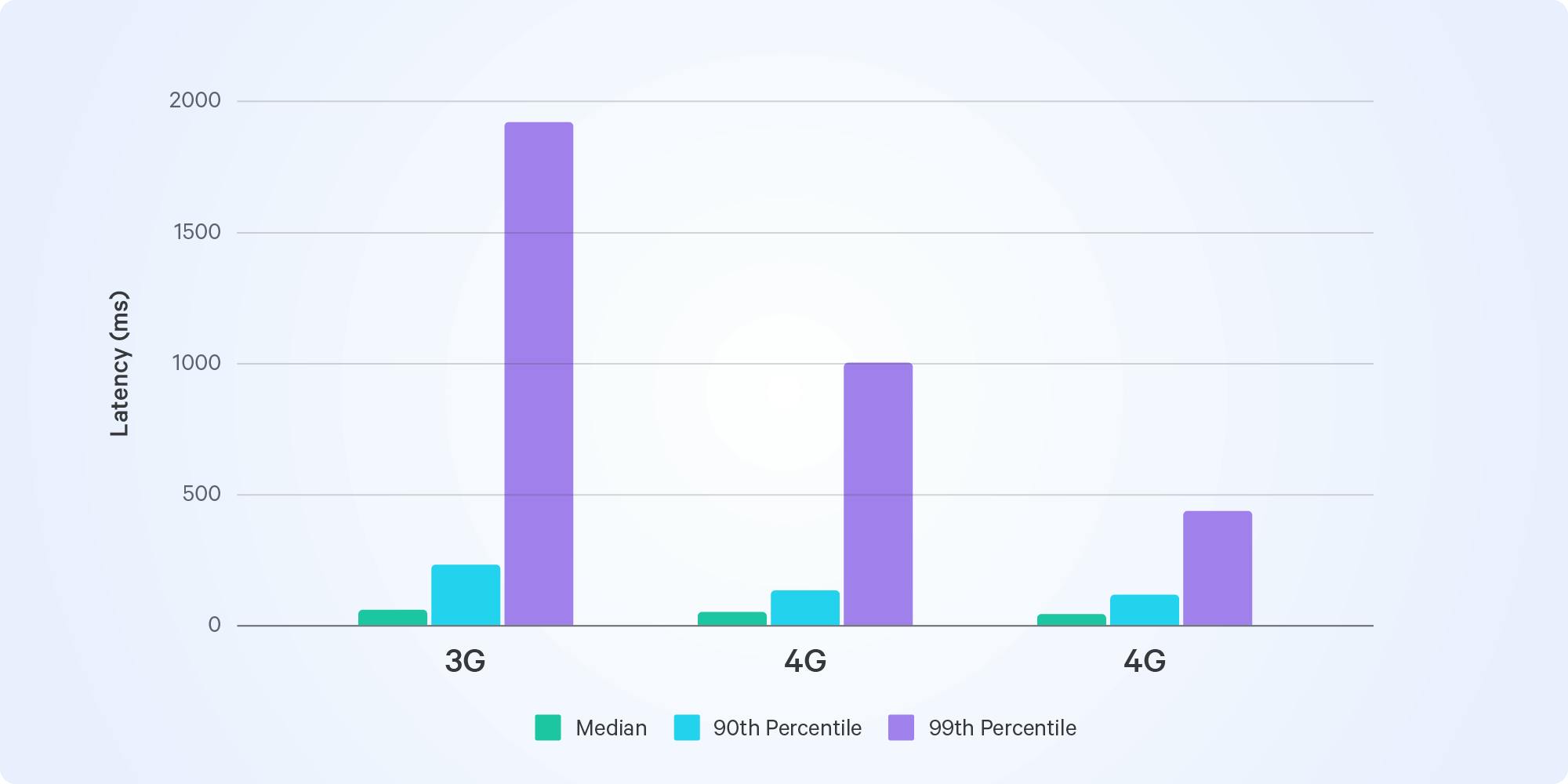
Latency on different mobile network generations
Contiguous latency and loss
This test is an optional extension to the UDP Latency/Loss test. It records instances when two or more consecutive packets are lost to the same test server. Alongside each event we record the timestamp, the number of packets lost and the duration of the event.
By executing the test against multiple diverse servers, a user can begin to observe server outages (when multiple probes see disconnection events to the same server simultaneously) and disconnections of the user's home connection (when a single probe loses connectivity to all servers simultaneously).
Typically, this test is accompanied by a significant increase in the sampling frequency of the UDP Latency/Loss client to one packet every 1.5s, or approximately ~2000 packets per hour given reasonable levels of cross-traffic. This provides a resolution of 2-4 seconds for disconnection events.

UDP jitter
This test uses a fixed-rate stream of UDP traffic, running between client and test node. A bi-directional 64kbps stream is used with the same characteristics and properties (i.e. packet sizes, delays, bitrate) as the G.711 codec. This test is commonly used to simulate a synthetic VoIP call where a real SIP server is unavailable.
The client initiates the connection, thus overcoming NAT issues, and informs the server of the rate and characteristics that it would like to receive the return stream with.
The standard configuration uses 500 packets upstream and 500 packets downstream.
The client records the number of packets it sent and received (thus providing a loss rate), and the jitter observed for packets it received from the server. The server does the same, but with the reverse traffic flow, thus providing bi-directional loss and jitter.
Jitter is calculated using the PDV approach described in section 4.2 of RFC5481. The 99th percentile will be recorded and used in all calculations when deriving the PDV.
Responsiveness (latency under load)
The responsiveness test aims to measure the responsiveness under working conditions of the internet connection, also variously referred to as working latency, bufferbloat or latency under load. The SamKnows responsiveness test specifically attempts to measure the queuing latency under network congestion.
The methodology is based on the “Responsiveness Under Working Conditions” draft (version 2) by the IETF IP Performance Measurement working group.
Test Concept
The core idea of the test is to make many latency probes (round-trip-time measurements) of different kinds in both unloaded and loaded (“working”) conditions.
The loaded conditions consists of as much throughput as possible being sent through a number of TCP connections in order to create network congestion and fill intermediate network queues/buffers. The generated load is either all in the uplink direction, or all in the downlink direction.
Test Sequence
The test sequence has three phases:
1. Pre-test Latency Probing
During this phase, the test makes regular latency measurements to establish the baseline latency from the client to the test server. After a fixed time of taking measurements, the test moves on to the next phase.
2. Warm-Up
The client communicates with the test server via a TCP connection and starts a test “session” on a control connection which remains unused during the test.
The test client then establishes a fixed number of TCP connections to the test server and starts either sending or receiving data as fast as possible on each. The total throughput across all connections is monitored and when it reaches a condition of stability, the warm-up is terminated and the test moves on to the next phase.
The conditions of stability can be different according to the test parameters:
- the total throughput across all connections as measured by the test client having variance of less than 15% over the last second
- the total throughput across all connections as measured by the receiver (which is the server in the case of an upload test) having variance of less than 15% over the last second
- the total throughput across all connections as measured by the test client having variance of less than 15% over the last second, followed by the last 4 values of the median round-trip-time aggregated over a 250ms window having a variance of less than 15%
Based on a test parameter, the test can either fail or continue if the warm-up stage does not reach stability within a given time limit.
3. Working Latency Measurement
During this phase, the high-load traffic is maintained by the client and server, whilst a large number of latency measurements are made.
Once the requested test time window has elapsed the load-generating connections are closed and the latency measurements are stopped.
The client then uses the control connection to download the server’s measured results for the test session, including the transfer counters over time (in order to compute the received speed for upload tests) and the estimated load connection TCP round-trip-time over time (in order to have valid RTT estimates for download tests, as only the sending side can observe the RTT).
The test client then computes a variety of summary statistics from the collected data on both the server and client and outputs them for collection.
Latency Probes
Each kind of latency probe under a certain condition is referred to as a “class” of latency probe.
Latency probes on load-generating connections are taken as estimates of the TCP connection round-trip time. These are computed based on the time between a segment being transmitted and the ACK being received. Notably, it does not include the contribution of dropped packets and retransmissions.
Latency probes on separate, dedicated connections are taken by making a HTTP request to a route with a known short response body. As an application-layer end-to-end measurement, this does include the contribution of any dropped packets and retransmissions, as well as a small contribution of processing time from the server application (which is negligible compared to practical latency values between test clients and servers). The TCP connection establishment time and application (HTTP) round-trip time are recorded separately and reported separately.
The different classes measured are shown in the table below.
| Unloaded Connection | Loaded Connection (“Working Conditions”) | |
|---|---|---|
| Load-Generating Connections | (N/A) | Connection Round-Trip Time |
| Separate, Dedicated Connections | Connection Establish Time, Application Round-Trip Time | Connection Establish Time, Application Round-Trip Time |
The connection round-trip time of the load-generating connections is referred to as the “in-band” latency. It is measured in order to capture the effect of large buffers on the transmission path causing an excessively large send window within a single connection. For example, if two seconds of video streaming data is already in transmission queues at the time of the user moving the video cursor, it will take a minimum of two seconds to consume that data before any new video content can arrive.
The use of separate, dedicated connections with different source port numbers is in order to capture the effect of one application’s internet traffic on another - for example, a user carrying out a bulk transfer while making a video call. The amount of queuing latency incurred in probes of this kind depends on the flow-queuing method being performed on the bottleneck link.
Being able to measure and report on these two different types of queuing latency is one of the key benefits of this test.
Test Output
The key output from this test is:
- Estimated responsiveness value from the IETF draft in “RPM” (round-trips per minute)
- Throughput of all load-generation threads during the latency measurement period
- For loaded conditions, the TCP round-trip time measurements of the load generation connections (min, 25/50/75/90/95/99th percentiles, max, mean)
For both loaded and unloaded network conditions:
- TCP connection establishment time (min, 25/50/75/90/95/99th percentiles, max, mean) for a dedicated connection latency probe
- Application data round-trip time (min, 25/50/75/90/95/99th percentiles, max, mean) for a dedicated connection latency probe
Extensions to IETF IPPM Responsiveness Draft 02
Quiescent Connection Latency Measurement
The IETF draft was written with a context of user-triggered testing on a consumer device (such as a laptop, desktop or mobile phone) in mind. Our test runs in the context of the SamKnows Router Agent, which monitors for cross-traffic, and therefore the test can be run with knowledge that the local network is not currently in use.
This means that the SamKnows test can collect baseline latency measurements to the same test server using the same protocol as under the loaded test condition. This allows insight into not only the responsiveness under working conditions, but also the increase in latency when the line is saturated.
Static Thread-Count Ramp-Up
The IETF draft was written to define a test procedure that would saturate network conditions for purposes of measuring responsiveness without any knowledge of the network that the device is operating on. For that reason, the draft defines a ramp-up procedure which progressively adds threads until the throughput and latency no longer increases.
The SamKnows Router Agent runs tests according to a schedule set centrally and with knowledge of the device ISP, package and access technology. For this reason, a value can be picked for number of threads required to complete ramp-up as quickly as possible in order to reduce the load on the test servers.
This approach also mitigates instability caused by dynamically adding connections or working threads on the relatively constrained computing environments that host the Router Agent.
Copying Reduction
Many devices on which the SamKnows Router Agent runs (such as home WiFi routers) are cost-sensitive devices, designed to optimise performance of routing traffic. As such they are not optimimised for the use-case of sending traffic through TCP connections which terminate on the device itself - the application CPU, memory bus or many other components could be a bottleneck.
In order to make sure that our test is able to saturate the network link on as many devices as possible, we make several optimisations to minimise the processing of data by the test application. In the case of downlink tests, the actual application data sent over the load-generating threads is not copied out of the network stack. In the case of uplink tests, the application data that is sent is a constant buffer to avoid having to load or generate data on the fly.
This means our test cannot conduct a higher-level application protocol like HTTP/2 or TLS as specified in the IETF draft in order to enable multiplexed application latency probes. As a result, we do not directly measure:
- the application layer round-trip-time (RTT), or
- the TLS session establishment time.
As a proxy for the application layer RTT, the TCP stack estimate of the RTT used. This estimate is computed by recording the average time between a TCP segment being transmitted and the sender receiving the acknowledgement. Because not every TCP segment is acknowledged, and because the estimate is averaged over time, this does not accurately capture the effect of individual packet losses and retransmissions in the same way as the IETF draft specifies, however it is the best available estimate.
As a result of the TLS session establishment times being undefined, the exact formula for the responsiveness value in RPM cannot be used. However, the spirit of the draft is maintained and the average of the trimmed means for each available class of latency probe under loaded conditions is still used.
Example
We used data from our Responsiveness (latency under load) test to show how a relatively unknown but common cause of high latency that can badly affect video streaming, online gaming, and teleconferencing. Find out more about bufferbloat in our Spotlight article.
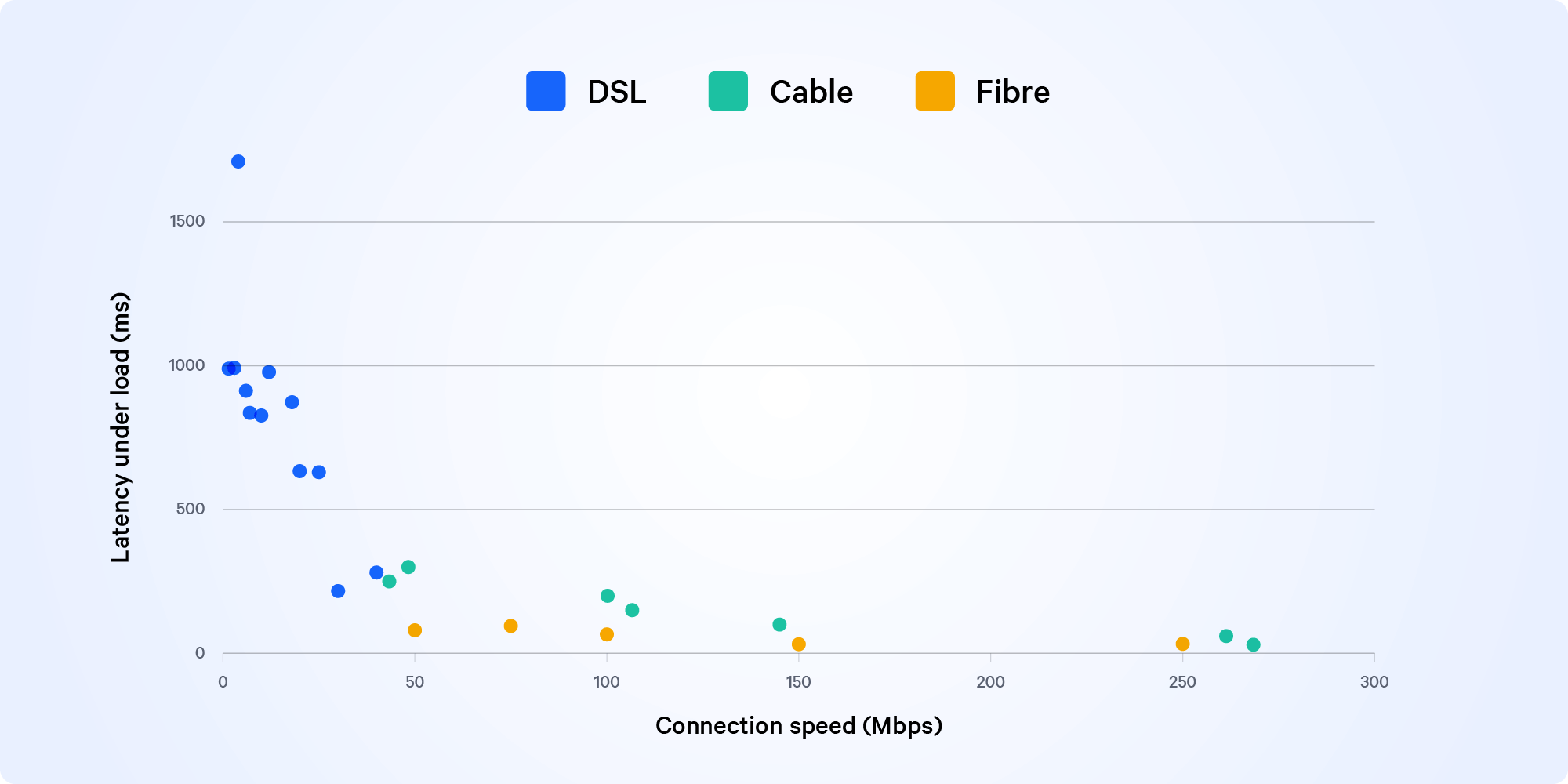
Chart showing latency under load vs connection speed